In Österreich wird ja das Thema DSGVO (Datenschutzgrundverordnung) aktuell etwas stark Propagiert.
Ein Kunde möchte dazu in seinem CRM die von Kunden retournierten Zustimmungserklärungen speichern. Ursprünglich war angedacht den gesamten Fragebogen auszuwerten. Da aber ein großteil der Kunden noch jedemenge andere Informationen handschriftlich am Zettel vermerkt hatten und der Preis für eine entsprechende Scansoftware recht hoch war. Wurde kurzerhand entschieden dass der Fragebogen durch die Firma MDS manuell ins CRM eingetragen werden.
Die Belege mussten aber dennoch gescannt werden damit Sie im CRM abgelegt werden konnten. Für den automatischen Import am besten ein PDF pro Datenblatt und der Dateiname=die KundenNr.
Da lt. Scannerhersteller dazu ebenfalls eine eigene Software mit OCR und entsprechenden Kosten von nöten ist, wurden wir um Rat gefragt.
Wie der Artikel vermuten lässt, haben wir den Auftrag nach kurzer Recherche im Internet angenommen und umgesetzt. Das Ergebniss (Quellcode) könnt ihr unten downloaden.
Zur Umsetzung
Die Datenschutzerklärungen wurden mit einem Bürodrucker gescannt. Dieser bettet die gescannten Bilder in ein PDF ein.
Das PDF enthält also natürlich ein Bild und keine Schriftdaten.
Es musste also eine OCR Lesung her. Selbst eine solche zu Programmieren ist für uns beinahe unmöglich und rechnet Sich niemals. Also entschlossen wir uns für tesseract.
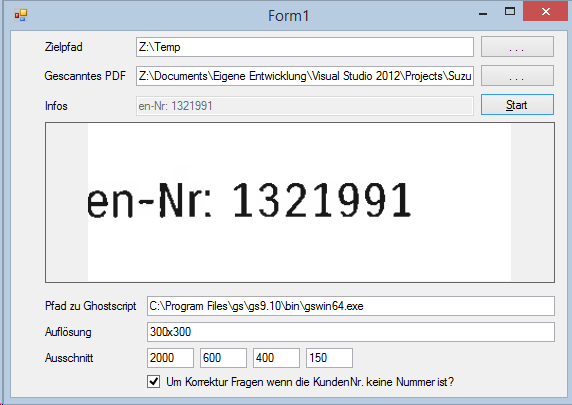
Für die einfachere Verarbeitung wurden das Scan-PDF (je PDF ca. 40 – 60 Datenschutzerklärungen) mithilfe von Ghostscript in ein Tiff konvertiert. Dadurch können die Einzelnen Seiten/Bilder mit den C# Boardmitteln weiterbearbeitet werden.
Jede Seite (Frame) im Tiff wird dann in C# in ein einzelnes Image gewandelt und der Teilbereich mit der KundenNr im Format „KundenNr: 12345678“ ausgeschnitten.
Dieser Ausschnitt wird dann an die Tesseract Engine übergeben.
Hier habe ich festgestellt, dass die Zahlen mit der Englischen tessdata (fertiges teachingfile für tesseract) besser erkannt werden. Sollte es hier Buchstaben enthalten, wird es nochmals mit der deutschen tessdata probiert. Besteht die KundenNr. dann immer noch nicht nur aus Zahlen, wird die Sachbearbeiterin befragt. Wobei ca. 90% korrekt automatisch mit tesseract erkannt werden.
Nachdem wir nun die Gescannte Seite als einzelnes Bild und die KundenNr. haben. Müssen wir nur noch das Bild mithilfe von PDFSharp unter der KundeNr. abspeichern.
Arbeitsaufwand inkl. Testen ca. 5 Std.
+ eine Erfahrung reicher => Dass war mein erstes mal mit tesseract.
Wir übernehmen natürlich keinerlei Haftung oder Garantie auf Funktion.
Anmerkungen:
- Es musste ein Ergebniss her => Sprich der Code ist Quick&Dirty und hat natürlich jedemenge Verbesserungspotential auch von der Performance.
- tesseract benötigt die VC 2015 runtime